MapReduce - Shuffle
对Map的结果进行排序并传输到Reduce进行处理 Map的结果并不是直接存放到硬盘,而是利用缓存做一些预排序处理 Map会调用Combiner,压缩,按key进行分区、排序等,尽量减少结果的大小 每个Map完成后都会通知Task,然后Reduce就可以进行处理
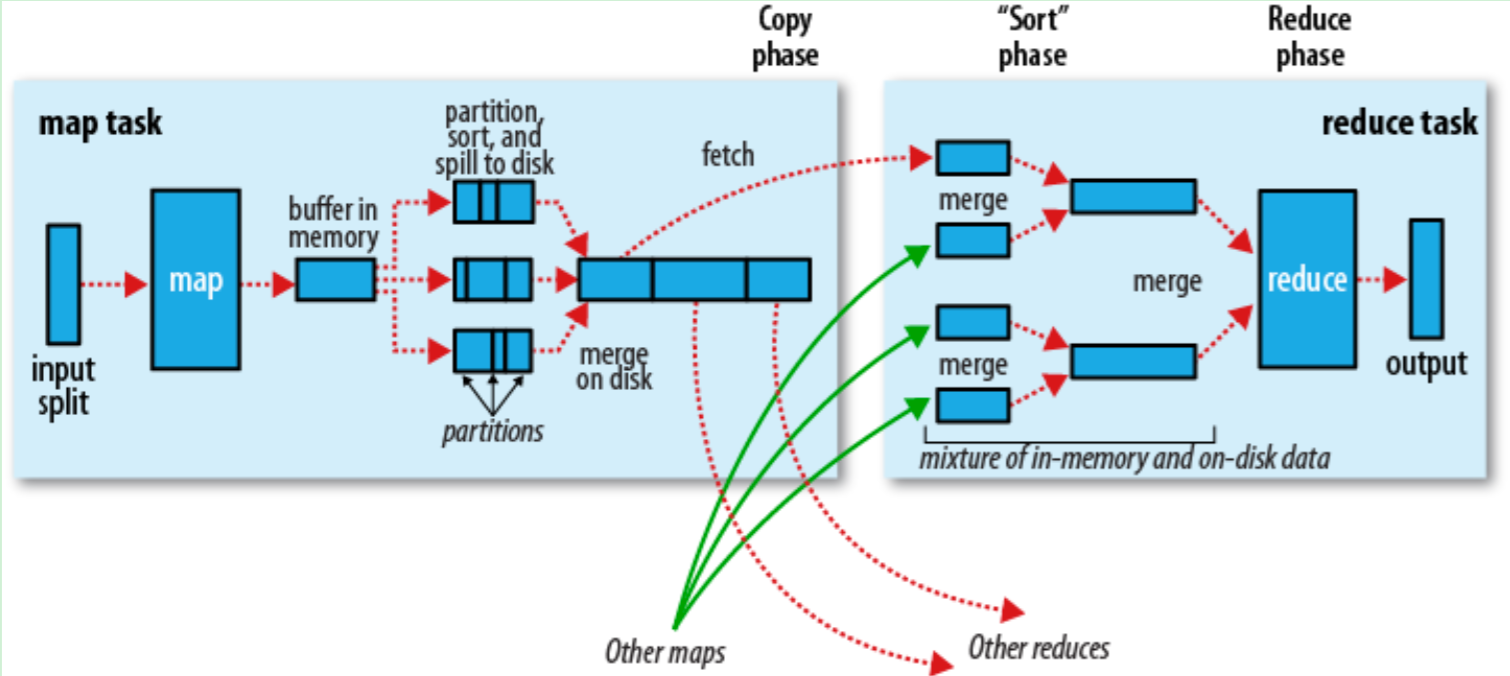
Map端
当Map程序开始产生结果的时候,并不是直接写到文件的,而是利用缓存做一些排序方面的预处理操作
每个Map任务都有一个循环内存缓冲区(默认100MB),当缓存的内容达到80%时,后台线程开始将内容写到文件,此时Map任务可以继续输出结果,但如果缓冲区满了,Map任务则需要等待
写文件使用round-robin方式。在写入文件之前,先将数据按照Reduce进行分区。对于每一个分区,都会在内存中根据key进行排序,如果配置了Combiner,则排序后执行Combiner(Combine之后可以减少写入文件和传输的数据)
每次结果达到缓冲区的阀值时,都会创建一个文件,在Map结束时,可能会产生大量的文件。在Map完成前,会将这些文件进行合并和排序。如果文件的数量超过3个,则合并后会再次运行Combiner(1、2个文件就没有必要了)
如果配置了压缩,则最终写入的文件会先进行压缩,这样可以减少写入和传输的数据
一旦Map完成,则通知任务管理器,此时Reduce就可以开始复制结果数据
Reduce端
Map的结果文件都存放到运行Map任务的机器的本地硬盘中
如果Map的结果很少,则直接放到内存,否则写入文件中
同时后台线程将这些文件进行合并和排序到一个更大的文件中(如果文件是压缩的,则需要先解压)
当所有的Map结果都被复制和合并后,就会调用Reduce方法
Reduce结果会写入到HDFS中
调优
一般的原则是给shuffle分配尽可能多的内存,但前提是要保证Map、Reduce任务有足够的内存
对于Map,主要就是避免把文件写入磁盘,例如使用Combiner,增大io.sort.mb的值
对于Reduce,主要是把Map的结果尽可能地保存到内存中,同样也是要避免把中间结果写入磁盘。默认情况下,所有的内存都是分配给Reduce方法的,如果Reduce方法不怎么消耗内存,可以mapred.inmem.merge.threshold设成0,mapred.job.reduce.input.buffer.percent设成1.0
在任务监控中可通过Spilled records counter来监控写入磁盘的数,但这个值是包括map和reduce的
对于IO方面,可以Map的结果可以使用压缩,同时增大buffer size(io.file.buffer.size,默认4kb)
配置
| 属性 | 默认值 | 描述 |
|---|---|---|
| io.sort.mb | 100 | The size of the memory buffer to use while sorting map output. |
| io.sort.record.percent | 0.05 | The proportion of io.sort.mb reserved for storing record boundaries of the map outputs. The remaining space is used for the map output records themselves. This property was removed in releases after 1.x, as the shuffle code was improved to do a better job of using all the available memory for map output and accounting information. |
| io.sort.spill.percent | 0.80 | The threshold usage proportion for both the map output memory buffer and the record boundaries index to start the process of spilling to disk. |
| io.sort.factor | 10 | The maximum number of streams to merge at once when sorting files. This property is also used in the reduce. It’s fairly common to increase this to 100. |
| min.num.spills.for.combine | 3 | The minimum number of spill files needed for the combiner to run (if a combiner is specified). |
| mapred.compress.map.output | false | Compress map outputs. |
| mapred.map.output.compression.codec | DefaultCodec | The compression codec to use for map outputs. |
| mapred.reduce.parallel.copies | 5 | The number of threads used to copy map outputs to the reducer. |
| mapred.reduce.copy.backoff | 300 | The maximum amount of time, in seconds, to spend retrieving one map output for a reducer before declaring it as failed. The reducer may repeatedly reattempt a transfer within this time if it fails (using exponential backoff). |
| io.sort.factor | 10 | The maximum number of streams to merge at once when sorting files. This property is also used in the map. |
| mapred.job.shuffle.input.buffer.percent | 0.70 | The proportion of total heap size to be allocated to the map outputs buffer during the copy phase of the shuffle. |
| mapred.job.shuffle.merge.percent | 0.66 | The threshold usage proportion for the map outputs buffer (defined by mapred.job.shuf fle.input.buffer.percent) for starting the process of merging the outputs and spilling to disk. |
| mapred.inmem.merge.threshold | 1000 | The threshold number of map outputs for starting the process of merging the outputs and spilling to disk. A value of 0 or less means there is no threshold, and the spill behavior is governed solely by mapred.job.shuffle.merge.percent. |
| mapred.job.reduce.input.buffer.percent | 0.0 | The proportion of total heap size to be used for retaining map outputs in memory during the reduce. For the reduce phase to begin, the size of map outputs in memory must be no more than this size. By default, all map outputs are merged to disk before the reduce begins, to give the reducers as much memory as possible. However, if your reducers require less memory, this value may be increased to minimize the number of trips to disk. |