Hadoop - MapReduce
简介
一种分布式的计算方式
指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组
Pattern
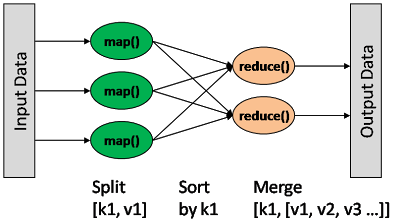
map: (K1, V1) → list(K2, V2)
combine: (K2, list(V2)) → list(K2, V2)
reduce: (K2, list(V2)) → list(K3, V3)
Map输出格式和Reduce输入格式一定是相同的
基本流程
MapReduce主要是先读取文件数据,然后进行Map处理,接着Reduce处理,最后把处理结果写到文件中
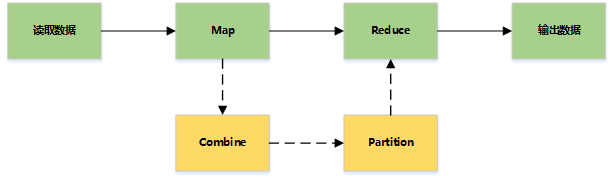
详细流程
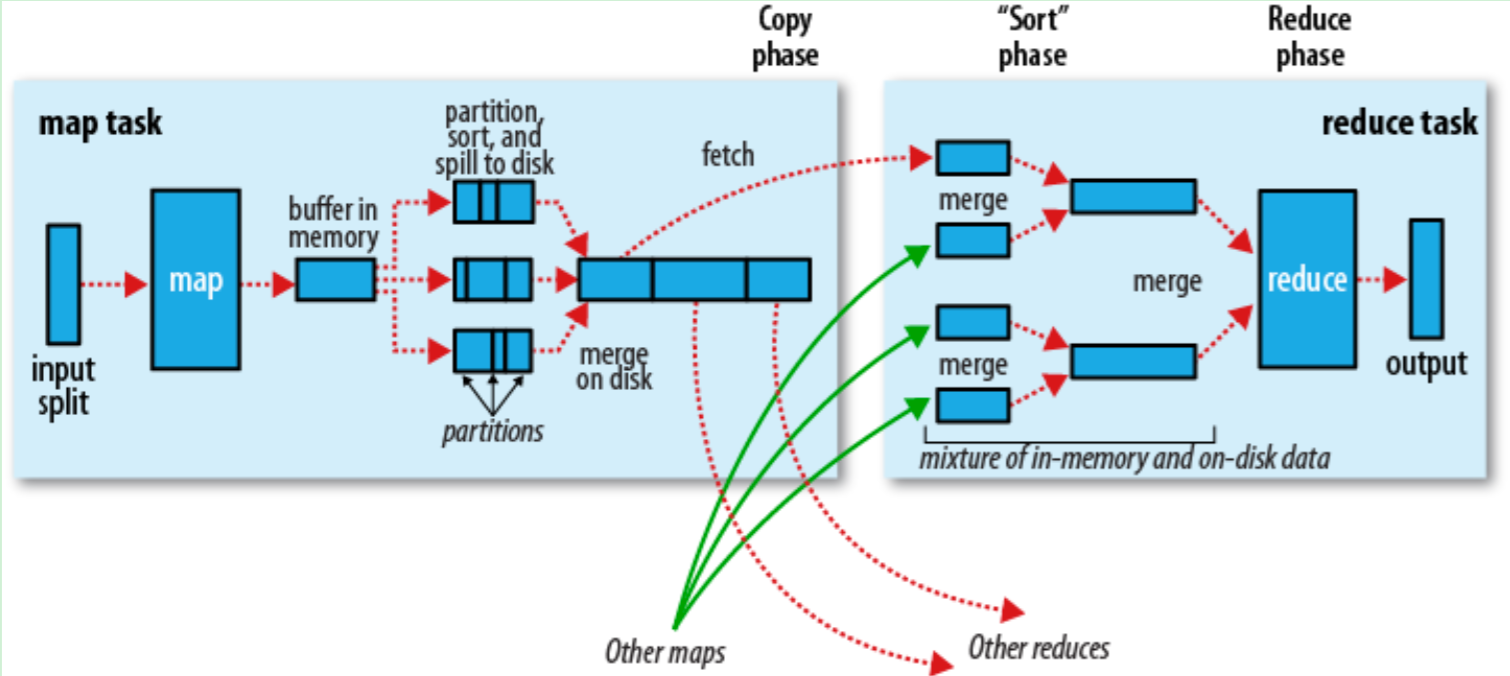
多节点下的流程
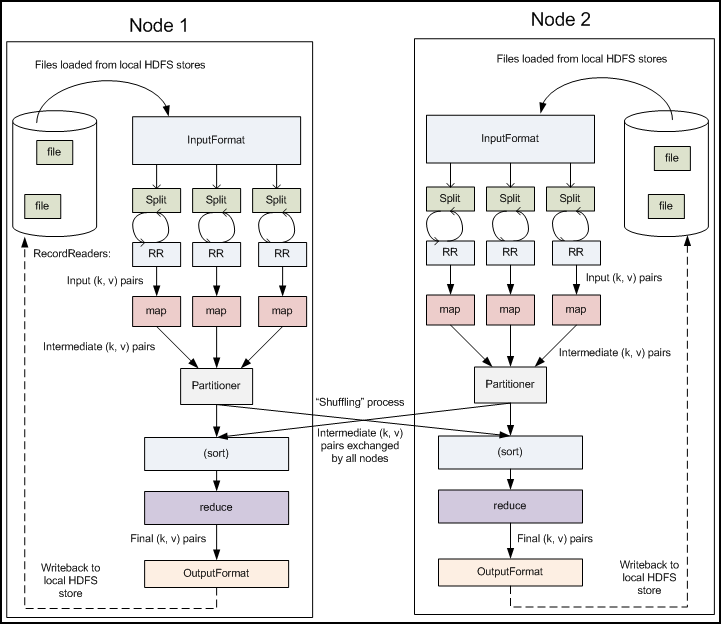
主要过程

Map Side
Record reader
The record reader translates an input split generated by input format into records. The purpose of the record reader is to parse the data into records, but not parse the record itself. It passes the data to the mapper in the form of a key/value pair. Usually the key in this context is positional information and the value is the chunk of data that composes a record. Customized record readers are outside the scope of this book. We generally assume you have an appropriate record reader for your data.
Map
In the mapper, user-provided code is executed on each key/value pair from the record reader to produce zero or more new key/value pairs, called the intermediate pairs. The decision of what is the key and value here is not arbitrary and is very important to what the MapReduce job is accomplishing. The key is what the data will be grouped on and the value is the information pertinent to the analysis in the reducer. Plenty of detail will be provided in the design patterns in this book to explain what and why the particular key/value is chosen. One major differentiator between MapReduce design patterns is the semantics of this pair.
Combiner
The combiner, an optional localized reducer, can group data in the map phase. It takes the intermediate keys from the mapper and applies a user-provided method to aggregate values in the small scope of that one mapper. For example, because the count of an aggregation is the sum of the counts of each part, you can produce an intermediate count and then sum those intermediate counts for the final result. In many situations, this significantly reduces the amount of data that has to move over the network. Sending (hello world, 3) requires fewer bytes than sending (hello world, 1) three times over the network. Combiners will be covered in more depth with the patterns that use them extensively. Many new Hadoop developers ignore combiners, but they often provide extreme performance gains with no downside. We will point out which patterns benefit from using a combiner, and which ones cannot use a combiner. A combiner is not guaranteed to execute, so it cannot be a part of the overall algorithm.
Partitioner
The partitioner takes the intermediate key/value pairs from the mapper (or combiner if it is being used) and splits them up into shards, one shard per reducer. By default, the partitioner interrogates the object for its hash code, which is typically an md5sum. Then, the partitioner performs a modulus operation by the number of reducers: key.hashCode() % (number of reducers). This randomly distributes the keyspace evenly over the reducers, but still ensures that keys with the same value in different mappers end up at the same reducer. The default behavior of the partitioner can be customized, and will be in some more advanced patterns, such as sorting. However, changing the partitioner is rarely necessary. The partitioned data is written to the local file system for each map task and waits to be pulled by its respective reducer.
Shuffle and Sort
The reduce task starts with the shuffle and sort step. This step takes the output files written by all of the partitioners and downloads them to the local machine in which the reducer is running. These individual data pieces are then sorted by key into one larger data list. The purpose of this sort is to group equivalent keys together so that their values can be iterated over easily in the reduce task. This phase is not customizable and the framework handles everything automatically. The only control a developer has is how the keys are sorted and grouped by specifying a custom Comparator object.
Reduce
The reducer takes the grouped data as input and runs a reduce function once per key grouping. The function is passed the key and an iterator over all of the values associated with that key. A wide range of processing can happen in this function, as we’ll see in many of our patterns. The data can be aggregated, filtered, and combined in a number of ways. Once the reduce function is done, it sends zero or more key/value pair to the final step, the output format. Like the map function, the reduce function will change from job to job since it is a core piece of logic in the solution.
Output format
The output format translates the final key/value pair from the reduce function and writes it out to a file by a record writer. By default, it will separate the key and value with a tab and separate records with a newline character. This can typically be customized to provide richer output formats, but in the end, the data is written out to HDFS, regardless of format. Like the record reader, customizing your own output format is outside of the scope of this book, since it simply deals with I/O.